導入
バイオインフォマティクスでは、配列アラインメント(またはシーケンシャル アラインメント) は、DNA、RNA、または一次タンパク質配列の構成要素 (ヌクレオチドまたはアミノ酸) を配置して、歴史的性質の類似性または非類似性を反映する一致領域を特定する方法です。整列されたシーケンスは伝統的に行列の行として表されます。穴は、連続する列に共通の文字を揃えるように配置されています。
アライメントは特に次の目的で使用されます。
- 機能部位を特定する
- タンパク質の機能を予測する
- タンパク質の二次 (または三次) 構造を予測する
- 系統発生を確立する
アラインメント内の 2 つの配列が共通の祖先を共有する場合、不一致は突然変異点、または挿入または欠失の場所として解釈されます。

使用
生命がどのように機能するかを理解する上で、タンパク質は重要な役割を果たします。したがって、我々は、類似した配列を持つタンパク質は同一の物理化学的特性を持つ可能性が非常に高いという仮説から出発します。作用機序がわかっている最初のタンパク質の配列と、作用機序がわかっていない 2 番目のタンパク質の配列間の類似性の同定から、未知の配列の構造的または機能的類似性を推測し、想定されている配列を実験的に検証することを提案できます。行動行動。
スコアと比較マトリックス
ほとんどの生物学的配列アラインメント法、特にタンパク質配列アラインメント法は、アラインメント スコアの最適化を目指しています。このスコアは、比較される 2 つの配列間の類似率に関連付けられます。一方では 2 つの配列間の同一アミノ酸の数が考慮され、他方では物理化学レベルでの類似アミノ酸の数が考慮されます。 2 つの配列内で、リジン(K) とアルギニン(R) など、2 つの非常に近いアミノ酸が並んでいる場合、保存的置換と言います (これら 2 つのアミノ酸の側鎖は両方とも正電荷を帯びています)。
これには、指定された 2 つのアミノ酸間の同一性または類似性スコアの正式な定義が必要でした。これにより、アミノ酸aが酸bで置換された場合に得られるすべてのスコアM(a,b)をリストする類似性行列M が生成されました。これらの 20 x 20 行列 (20 アミノ酸用) には、構築方法が異なるものがいくつかあります。最も古典的なものを挙げると次のとおりです。
- 種間の進化的距離に基づく PAM (許容される突然変異の確率) と呼ばれるデイホフ行列
- 置換の情報内容に基づく BLOSUM と呼ばれるヘニコフ行列
各ファミリーには、さまざまなストリンジェンシーをもついくつかの一連のマトリックスが存在するため、アミノ酸置換に対して多かれ少なかれ耐性があります。
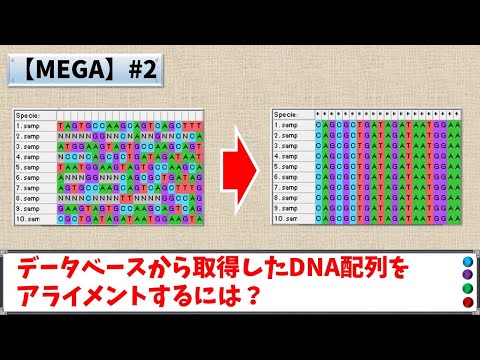
表現
通常、配置はグラフィックまたはテキスト形式で表されます。シーケンシャル アラインメントのほとんどの表現では、シーケンスは行に書かれ、共通のコンポーネントが連続する列に現れるように配置されます。テキスト形式では、整列された列には同じまたは類似の文字が含まれており、一貫した記号体系で示されます。アスタリスクは列間の同一性を示すために使用されます。多くのプログラムは情報を区別するために色を使用します。 DNA または RNA の場合、色を使用することでヌクレオチドを区別することができます。タンパク質のアラインメントの場合、アミノ酸の特性を示すことができ、置換されたアミノ酸の役割の保存について結論付けるのに役立ちます。
複数の配列が含まれる場合、合意に達するために最後の行が追加されます。
アライメントには 2 つのタイプがあり、その複雑さに応じて異なります。
- 2 つの配列のアラインメントからなるペアワイズ アラインメントは、多項式複雑さアルゴリズムを使用して実現できます。アライメントを実行することが可能です。
- グローバル、つまり全長にわたる 2 つのシーケンス間 ( FASTA )
- シーケンスと他のシーケンスの一部の間のローカル (BLAST)
- グローバル アライメントであるマルチプル アライメントには、3 つ以上のシーケンスのアライメントが含まれ、データのサイズに応じて指数関数的な計算時間と記憶領域が必要になります。
シーケンシャル アライメントは、使用する特定のプログラムに応じて、さまざまなファイル形式で提供できます: FASTA 形式、GenBank など。ただし、研究室では、技術ツールの特殊な使用により、形式の選択肢が減る可能性があります。