記述統計は、比較的大規模なデータセットを記述するために使用される多数の手法をまとめた統計学の分野です。
統計的説明
記述統計の目的は、大量のデータがある場合に利用可能なデータを統計を使用して説明、つまり要約または表現することです。
利用可能なデータ
現象を説明するには、その現象について特定のことを観察したり知ったりする必要があります。
- 利用可能な観測は常に同期観測セットで構成されます。例: 特定のタンク内の特定の時間における温度、圧力、密度の測定値。これら 3 つの同期変数は、複数の場所 (複数のタンク) で (複数の日付に) 複数回観察できます。
- 利用可能な知識は、特定の変数を結び付ける式で構成されます。たとえば、理想気体の法則P V = n R Tです。
説明
現象を可能な限り最善に説明することは非常に複雑です。統計の文脈では、現象に関して入手可能なすべての情報をできるだけ少ない図と言葉で提供する必要があります。
通常、理想気体の法則は、圧力、温度、体積のみが観察される平衡状態にある気体の挙動からなる現象を非常によく説明します。定数Rの値は、この記述に関連付けられた統計として見ることができます。
視覚的な説明の問題も生じますが、それは一旦脇に置きます。データ視覚化の記事では、これについてより直接的に答えています。
統計的な観点
現象の記述に関する統計的な観点は、利用可能な観察が同じ抽象的な現象の異なる実現であると考えることから生まれます。数瞬間にわたって測定された温度、圧力、密度の例を続けるために、これら 3 つの測定を行うたびに同じ現象が観察されると考えます。測定値はまったく同じではありません。統計的に説明するのは、これらの測定値の分布です。
例
物理量

タンク内に存在するガスの圧力、温度、密度を時々測定すると、測定の瞬間によってインデックス付けされた、3 つのデータの集合が得られます。
行動量または生物学的量
たとえば医療分野では、複数人の薬を服用する前後の体重を測定できます。次に、人の名前によってインデックス付けされたデータのペア (前後の体重) のコレクションを取得します。
社会学やマーケティングでは、多くの人が年間に読んだ本の数を測定でき、その年齢や学習レベルもわかっています。ここでも、ドライブの名前でインデックス付けされたデータ トリプルのコレクションを取得します。
実際の事例の定式化
測定されたさまざまな量は変数と呼ばれます。
統計的研究では、これらの変数 (およびおそらく他の変数) を実装する多かれ少なかれ隠れた抽象的な現象が存在すると仮定する必要があります。
各インデックス値 (日付または個人を識別する番号) によって、現象の部分的な写真が特定されます。特定の指標の変数の値を観測値または現象の実現と呼びます。
形式的な観点から、抽象的な現象にはランダムな要素(確率的とも言います)だけでなく決定的な要素も含まれる可能性があると仮定します。観測された変数はすべて、データ ベクトルの形式で並べられます。変数は1 つだけです (ただし、これは多変量です)。
したがって、観測値は実際に、この多変量確率変数を (数学的統計の意味で) 実現したものになります。
単一変数の研究
単変現象の説明
最も単純な状況から始めましょう。単一の変数 (タンク内の圧力や、人が年間に読む本の数など)を観察する状況です。上で見たように、この変数が一部である現象があり、この現象はおそらく部分的にランダムであると仮定します。このランダムな部分は、観測された変数が部分的に未知のハザードの影響を受ける抽象変数に由来することを意味します。
したがって、私たちが利用できる観察は、この抽象的な確率変数を実現したものになります。
このフレームワークにおける記述統計の目的は、おそらく私たちの仮説 (これらすべての背後にある抽象的なランダム法則の存在) に基づいて、この値の集合を最もよく要約することです。
包括的な説明
最初の観察は、観察のコレクションに基づく現象の可能な限り最良の説明は、そのコレクション自体であるということです。確かに、すべてがそこにあるのに、なぜ多数の指標を計算して人生を複雑にするのでしょうか?
まず第一に、この発言は決して愚かなものではなく、ある観点から見ると、ノンパラメトリック統計の背後にこの哲学があることがわかるということに注意する必要があります。
しかし第二に、これらの観察を要約することは興味深いことがはっきりとわかります。そこで重要な問題は、含まれる情報を破壊することなくそれらを要約するにはどうすればよいかということです。
簡単な例
私たちの観察が走り高跳び競技における 23 人の選手の成功または失敗であるとします。それは、アスリートの名前によってインデックス付けされた一連の「成功」(S)、「失敗」(E) になります。データは次のとおりです。
S、S、E、E、E、S、E、S、S、S、E、E、S、E、S、E、S、S、S、S、E、E、S

統計的基準を考えたり使用したりせずに、この現象を次のように説明することができます。
- 23 人のアスリートのそれぞれに、ジャンプに成功した場合は 1 ポイントを与え、失敗した場合は 0 ポイントを与えないとすると、平均獲得ポイント数は 0.5652 となり、獲得ポイントの標準偏差は 0.5069 となります。
これはかなりあいまいな説明であり、成功と失敗のリストが 50 文字未満であるのに対し、この説明には 200 文字弱が含まれることに注意してください。おそらく、次の説明の方がよいでしょう。
- 23人の選手がジャンプし、そのうち13人が成功した。
この説明は単純かつ明確で短く (50 文字未満) です。
また、次のような情報を破壊する記述を行うことも十分に可能です。
- 各アスリートがジャンプに成功した場合は 1 ポイントを与え、失敗した場合は 0 ポイントを与えないため、平均獲得ポイントは 0.5652 になります。
実際、少なくとも重要な説明要素であるジャンパの数が欠落しています。
もちろん、特定の現象を説明しようとしている場合、たとえば、23 人のジャンパーの 1 人に賭けた場合、勝つチャンスはどのくらいあるでしょうか? 、答えは違っていたでしょう:
- 57%
はるかに短く、質問の観点から情報を破壊することはありません。それはもはや、特定の視点なしに、非常に正確な角度で現象の成果を説明するという問題ではありませんでした。私たちは実際には別の現象(賭けの現象) を説明しています。
したがって、質問に正しく答えることが非常に重要であり、既製の公式を考えなしに適用しないでください。
最後に、別の質問に焦点を当ててみましょう。今後のジャンプ競技に賭けなければならない場合、勝つ可能性はどのくらいですか? 。
前の質問と同様に 57% と答えることができましたが、結局観察されたジャンパーは 23 件だけでした。これは他のジャンパーのパフォーマンスについて結論を出すのに十分ですか?
答えを提供するために、使用する主な仮説を明確にします。
- 仮説:ジャンパーのパフォーマンスの性質は観察されたものと同じになるでしょう。
これは、この競技が国内的なものであれば、 2 番目の競技会も同様であることを意味します。同じ現象に関する国家レベルの現象からの観察を使用するのではなく、たとえばオリンピック レベルからの観察を使用します。
そして、この枠組みの中でも、たとえば、二人とも成功したジャンパーを 2 人だけ観察した場合、それはすべての国内レベルのジャンパーが常に成功することを意味することになるでしょうか (つまり、私が勝つ可能性は 100% でしょうか?)もちろん違います。
次に、 信頼区間の概念に頼らなければなりません。その目的は、特定の確率的仮説と組み合わせて、アスリートのサンプルのサイズを説明することです。
この場合、数学的統計は、「 N 個の観測値から計算された比率推定量は、理論的な比率pの周りの正規分散法則p (1 − p ) / Nに従う」ことを示しています。私たちの場合: N = 23およびp = 0.57 。これは、私たちの仮説の下では、95% の確率で、次の範囲内に勝利の可能性があることがわかります。
- 同様の試合で賭けに勝つ確率は 95% で、36 ~ 77% の間です。
方法論的要素
最終的には、説明目的に使用できる統計のコレクション全体が存在します。これらは、観測値の分布のさまざまな特性を定量化する基準です。
- それらは値を中心にしていますか?
- それらは特定の値に基づいてグループ化されていますか?
- 可能な値の広い範囲をカバーしていますか?
- 彼らは既知の統計法則に従っていますか?
- 等…
私たちに投げかけられた質問について先入観を持たずに、これらのさまざまな記述指標を検討することができます。
観測値の分布の固有の記述
私たちが尋ねている質問について何の先入観も持たずに、いくつかの簡単な統計によってそれを説明することができます。
最初の 2 つは位置基準と呼ばれることが多く、その他は分散基準のカテゴリに分類されます。
平均
算術平均は、変数の値の合計を個体数で割ったものです。
中央値
中央値は、サンプルを同じサイズの 2 つのグループ (50% 上と 50% 下) に分割する中心値です。中央値は平均値とは異なる値を持つ可能性があります。フランスでは、給与の中央値は平均給与よりも低く、最低賃金労働者が多く、非常に高い給与を支払う人はほとんどいません。しかし、給与が高いと平均値も押し上げられます。
一般に、中央値は、順序付けされた系列において、M 以下の値と同じ数の M 以上の値が存在するような値 M です。
モード
このモードは、最も頻繁に実現される実現に対応します。
分散
修正された経験的分散
注意してください: 等分散 (記述統計の概念) は、観察された算術平均からの偏差の 2 乗の単純な算術平均ですが、不偏分散 ( 数学的統計の概念、つまり、データ サンプルのサイズが大きくなる傾向があることを意味します) は、無限大に向かうにつれて、統計量 (ここでは分散) は理論値に向かう傾向があります) は、観察された分散のn / ( n − 1)倍になります。したがって、不偏分散は観察された分散よりも大きくなります。
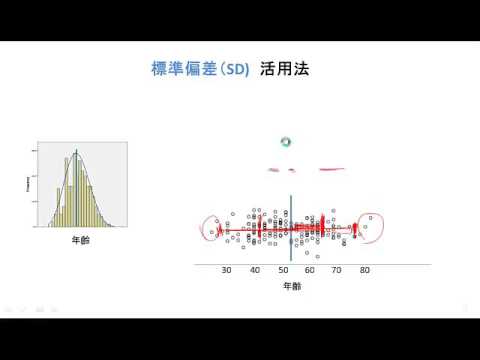
標準偏差
- 変動係数: $$ {C.V. = \frac{\sigma}{\bar{x}}} $$
最小値と最大値
- Range : これは最小値と最大値の間の間隔です。現象の範囲(または分散)が大きい場合、その現象は「強いダイナミクス」を持つと言われます。
信頼区間
大数の法則により、推定平均値が次のとおりであることが保証されます。
したがって、サンプル サイズnが直線的に増加するにつれて、平均推定量の精度は増加します。
n点のセットが母集団のサンプルではなく母集団全体を構成する場合、推定のコンテキストではなく測定のコンテキストにいるため、不偏分散を使用する必要はありません。
分位数
これらは、分布を 2 つの等しい部分に分割する中央値の概念を一般化します。特に、母集団の四分位、十分位、パーセンタイル (またはパーセンタイル) を昇順に定義し、同じサイズの 4、10、または 100 の部分に分割します。
したがって、人口の最初の 90% と残りの 10% を分ける値を示すために「90 パーセンタイル」について説明します。したがって、幼い子供の集団では、身長または体重がパーセンタイル90 を超えるか、パーセンタイル 10 を下回る子供は、特別な監視の対象でなければなりません。
ヒストグラム
多くの人がヒストグラムをグラフ表現と考えており、したがってデータ視覚化手法の説明においてその役割が大きいとしても、既知の統計法則と比較すると、ヒストグラムはデータの網羅的な表現と説明の間の自然なつながりとなります。
経験的分布
離散値変数の経験密度は、単に各値を取る観測値の割合です。
もう一度アスリートの例を見てみましょう。人口の経験密度は、成功が 57%、失敗が 43% です。関連するヒストグラムは非常に単純です (左の画像を参照)。
関連する経験的分布関数を、次の値を持つ一連の実数値観測値と呼びます。
これは、観察された現象のイベントの値がv以上の値を持つ確率の推定値です。
観測に関連する経験的な密度を推定したい場合は、 F * ( v )を導出する必要があります。インジケーターの導関数(
いくつかの代替案が考えられます。
- カーネル推定器を使用するには、次の密度の実装が含まれます。
- ステップ関数で密度を近似します。
ヒストグラムは、経験的な密度のステップ関数による最良の推定値です。つまり、ヒストグラムの積分はF * ( v )にできるだけ近くなければなりません。ヒストグラムの積分は区分的アフィン連続関数であることに注意してください。ある観点から見ると:
- 経験的分布関数を最もよく近似する連続区分的アフィン関数を見つけることは、ヒストグラムを完全に特徴付けることになります。
この文脈では、ピース (クラスまたはバー) の数が非常に重要なパラメーターです。可能な限り最高の値を見つけたい場合は、追加の基準を使用する必要があります。たとえば、 Akaike基準または BIC 基準 (ベイズ情報量基準) を取り上げます。情報またはエントロピー基準を使用することも可能です。
したがって、構造上、ヒストグラムのバーは必ずしもすべて同じ幅になるわけではありません。
(A) 点のランダムな描画 | (B) 関連するヒストグラム | (C) 関連する区分的アフィン連続関数 (赤) と経験的分布関数 (黒) |
ヒストグラムの構築
ヒストグラムは、統計データの多くの可能なグラフ表現のうちの 1 つです。分位数と同様に、ヒストグラムは母集団をクラスに分割しますが、視点が異なります。
分位数の目的は、同じサイズのクラス間の境界を見つけることです。これらは、たとえば収入の観点から 2 つの極端な階級を比較するためによく使用されます。
ヒストグラムの場合、観測値の実際の分布を最もよく反映するようにクラス幅が選択されます。これは難しい作業です。
簡単にするために、ヒストグラムのクラスは同じ幅と可変の高さを持つとみなされることがあります。そのようなヒストグラムは棒グラフと呼ばれます。これらは実際のヒストグラムではありません。

これら 2 つの曲線間の距離を比較することができます。
- たとえば、コルモゴロフ・スミルノフ検定を使用する
- ここで、これら 2 つの曲線間の距離 (曲線間の表面によって定義される) はΧ 2の法則に従うことに注目してください。
さらに言えば、この種の分布関数を比較する方法 (ここではヒストグラムから得られる分布と経験的分布の間) を使用して、観察の経験的分布を既知の法則 (つまり、たとえばヘンリーの原理) と比較することができます。右)。これは、私のディストリビューションが既知のディストリビューションに似ているか?という質問に答えるのに役立ちます。 。
観測値の分布の比較による説明
これには、観測値の分布を既知の統計法則と比較することが含まれます。
経験的な分布と統計的に区別できない既知の法則 (ガウス分布など) を特定すると、その情報を要約する非常に優れた方法が得られます。つまり、私の観察のような文章よりも説明的なものは、次の正規分布のように分布します。平均は0、標準偏差は0.2 ?
いくつかの変数の研究
原理は単一変数の場合と同じですが、すべての特性 (平均、最頻値、標準偏差など) が二変量 (ベクトル) である点が異なります。
一方で、相関関係という追加の特性もあります。これは、多変量変数のさまざまなコンポーネント間の依存関係の線形尺度です。
相互情報量(または条件付きエントロピー) など、2 つの変数間の依存性を測る他の尺度もあります。
測定以外にも、グラフィカル ツールやテーブルを使用して依存関係を調査することもできます。
データの分離
最も単純なテーブルは論理和です。 2 つの変数V 1とV 2 がある場合、たとえばいくつかの瞬間に観察されます。
- 2 番目の変数がより大きいもの$$ {V^*_2} $$;
- 2 番目の変数が以下のもの$$ {V^*_2} $$。
これら 2 つのセットが (平均、標準偏差、既知の分布との比較などのさまざまな単一基準に関して) 異なるほど、イベントはより多くなります。
いくつかのしきい値を使用してサンプルをいくつかの部分に分割することで、これを続けることができます。
次に、単一の変数 ( V 1 ) を持つS + 1 個のサンプルの母集団が存在することがわかり、これらは個別に調査できます。サンプルの分布が大きく異なることに気付いた場合、それは 2 つの変数間に依存関係があるためです。
ランダムな母集団 (2 番目の変数は表示されません) | 2 番目の変数をしきい値処理した後、3 つのグループが形成されます。 3 つの分布が大きく異なっていることがはっきりとわかります。したがって、2 つの変数の間には依存関係があります。 |